




前言
官方文档:https://docs.spring.io/spring-framework/docs/5.3.27/reference/html/
Spring指的是什么?
现在大多数时候说到Spring的时候,指的都是Spring家族的一整套产品,例如Spring Framework,Spring Boot,Spring Security等等。其实,这些产品之间并不是一定要组合使用,每一个项目都是独立的,都拥有自己的仓库、Release和相关文档。官方文档和本文中需要指出,出现的Spring一般都指的是其中最早最核心的一个产品——Spring Framework。
Spring Framework本身也由许多模块组成,用户可以根据自己的需要,只引入其中一部分模块(子项目)作为自己项目的依赖使用。其中比较有名的模块有:SpringMVC,而其中核心的模块有beans,context,aop等。
Spring Framework和Jave EE(Jakarta EE、J2EE)的关系究竟是怎么样的?
Spring Framework诞生于2003年,也就是Java EE标准刚提出不久。他和Java EE既不是包含关系,也不是Spring实现了Java EE标准。官方文档是如此介绍Spring和Java EE的关系的:Spring Framework集成(使用)了Java EE中的一部分技术标准,有Sevlet、WebSocket、Concurrency Utilities、JSON Binding、Bean Validation、JPA、JMS以及JTA/JCA。
Spring Framework的设计理念是怎么样的?
设计理念就是设计的价值观,决定了什么样的设计会被采用,为什么采用设计A而不是设计B。Spring Framework的设计中秉持以下五条理念:
- 任何时候,选择权交给用户。这意味着使用Spring Framework并不会被捆绑到某个其他具体技术实现上无法抽离,用户可以在任何时候方便地更换其他技术实现,例如数据库连接的方案。Spring Framework的实际带来了很好的正交性。
- 思路开放,从不限制用户该怎么做。在使用Spring Framework的过程中,用户不会被要求必须这样或者那样。很多情况下Spring都提供了多种多样的解决方案。
- 向后兼容。Spring确保旧的代码可以方便地使用新版本的框架。
- 精雕细琢的APIs。每一个API的设计都经过了细致打磨。
- 过硬的源码质量。源码质量非常高,保证无循环依赖,并配有良好的Javadoc。
核中核——IoC容器
容器
使用IoC容器最小依赖:
- org.springframework.beans
- org.springframework.context
最最基础版的容器接口:BeanFactory
常用的容器接口:ApplicationContext。它是BeanFactory的一个子接口,是BeanFactory功能的超集,提供了更多的功能。
将容器创建起来的时候,需要传入configuration metadata,也就是bean的配置信息。bean的配置信息有多重形式:xml(最原始)、Java注解、Groovy DSL脚本等。这个就是Bean的食谱,容器会根据食谱内容来创建Bean。
用户可以手动使用容器,比如通过applicationContext.getBean()方法用名称获得一个bean对象实例。但是Spring不建议用户这么做,因为这样会产生用户代码对Spring框架的不必要的依赖。所有这些依赖都可以在后面通过自动注入来完成解耦。
Bean
Bean的属性
一个容器中管理着多个Bean对象实例。每个Bean有一些基础属性:
- Class
- Name
- Scope
- Constructor arguments
- Properties
- Autowiring mode
- Lazy initialization mode
- Initialzation method
- Destruction method
Bean的命名
给Bean命名:可以用id给Bean起一个唯一的名字(在一个容器内必须唯一),或者用name给bean起别名。如果不显示指定名称,Spring会根据它的类名默认生成一个id,一般是第一个字母转小写(如果前几个字母都是大写则保持和类名一样)。通过别名alias获取一个bean和通过id获取的方法完全一样,都可以用getBean方法来获得。
Bean的alias不仅可以在Bean内部声明,也可以在外面单独指定。例如在xml中可以通过<alias name="fromName" alias="toName"/>的方式指定别名。
设置别名的意义是:对于一个很大的系统,有许多子系统,每个子系统单独都要使用一个dataSource,但是整合起来之后,需要所有子系统使用一个共同的dataSource。就可以在整合的系统中通过alias为一个dataSource的bean设置alias,符合子系统注入或ref的时候需要的name,就可以达到想要的效果了。
Bean的创建
创建一个Bean有几种方式:
- 使用构造方法。通常作为Bean的类都会有一个无参构造器,然后通过getter和setter来塑造其中的属性,因此可以很方便地交给容器来创建对象。对于不是那么标准的Bean类(例如遗产代码,没有无参构造器),也可以有一些手段传入构造器的参数调用有参构造器。
- 使用工厂的static方法。通过class指定工厂类,然后通过factory-method指定要调用的static类。这个static类返回的对象被作为Bean加入容器。
- 使用工厂的非static方法。这种情况下不能指定class,要在factory-bean中指定工厂的bean是哪一个名字,然后factory-method指定一个非static的方法来创建Bean。
依赖注入
依赖注入的两种方式
依赖注入有两种方式:
- 通过传入构造器参数,使用有参构造器创建Bean。如果使用上面所说的static工厂方法和非static工厂方法,也归类到这种方式中。使用的配置几乎是一模一样的。这也是官方更推荐的依赖注入方式。在xml配置中使用consturctor-arg声明。
- 通过setter依赖注入。这种依赖注入方式会在Bean创建完成后马上通过setter方法设置其中一些依赖的对象引用。setter方式注入的对象可以覆盖之前已经注入的依赖对象。在xml配置中一般通过property标签声明。
循环依赖问题:如果存在循环依赖,则两个Bean不能都通过构造器进行依赖注入,否则会抛出异常。唯一的解决方法是:至少有一个对象通过setter方式创建,Spring会先创建一个没有注入依赖的Bean半成品,最后再分别注入依赖。注意:不存在循环依赖时,无论是构造器依赖注入还是setter依赖注入,都会把被依赖的Bean完全创建、初始化好之后才会注入,因此有循环依赖时一种特例。
通过构造器注入依赖的时候,一般情况下注入的顺序就是构造器中参数声明的顺序。可以通过指定name、index来手动改变顺序(注意指定name需要打开debug编译选项,或者使用Spring提供的注解@ConstructorProperties)。注入的时候,值既可以是bean,也可以是单纯的简单类型(基本类型、字符串等),可以用type加以指定类型。
通过setter属性注入时,传入的数据类型也分多钟:
- Straight Values。包含基础类型和字符串等。这类的值可以直接用字面量写在xml文档中,用property标签的value属性,或者property下面的value子标签指定。property属性下面还可以指定idref,他的作用是对字符串进行检查,看是不是符合一个已有bean的id,没有就会报错,如果注入的属性类型不是String而是其他对象,则这里会尝试通过字符串调用有参构造函数构造一个对象来注入。
- 其他Bean的引用。通过ref标签声明,类似
<ref bean="someBean"/>。如果里面用bean,则可以引用该容器及父容器中的bean;如果里面改成parent=xxx,则只能引用父容器中的bean,这种用法推荐的用途是,在容器中使用一个代理对象来装饰父容器中的某个bean时,希望两个bean名字相同而且不出错,可以在声明代理bean的时候使用parent指向父容器中的bean。
内部Bean:可以在一个property或constructor-arg下面用bean标签声明内部Bean。内部Bean的id和名字都没有实际作用,而且只能在这里被用到,不能被外部使用。内部Bean的生命周期通常是和外部Bean保持相同。
集合属性的注入
java.util.List类型:
<property name="someList">
<list>
<value>a list element followed by a reference</value>
<ref bean="myDataSource" />
</list>
</property>
发现上面的List中既有String类型的变量,又有其他类型的bean。可以将属性定义为List<?>或者List<Object>实现。当然,也可以声明为强类型的List,例如List<String>,这样就不能注入bean这个类型了。
java.util.Map类型:
<property name="someMap">
<map>
<entry key="an entry" value="just some string"/>
<entry key="a ref" value-ref="myDataSource"/>
</map>
</property>
集合属性的合并:一个bean如果有parent(可以在bean标签内用parent属性定义),则该bean下面注入一个集合属性的时候,可以插入merge=”true” 这样的属性,启用集合合并。集合合并会将新定义的内容和原有parent bean中的集合进行并集。如果是Map有重复的key,会采用子Bean的value,而如果是List,则父Bean的元素在前,子Bean在后。
也可以把某个属性注入为null,只需要使用<null/>标签就可以了。
p-namespace
使用p-namespace可以简化属性(setter)注入的写法。使用时需要在xml的beans标签属性中加xmlns:p="http://www.springframework.org/schema/p"
原来的<property name="email" value="a@qq.com"/>可以简写为p:email="a@qq.com"。而对于引用其他bean的,可以简写为p:spouse-ref="jane",即加一个-ref后缀,作为一个bean标签的属性。
p后面直接跟上属性的名字,称为name notaion。
c-namespace
同样的,c-namespace是构造器注入的简化写法。使用时需要添加xmlns:c="http://www.springframework.org/schema/c"
注入的为value和ref的时候和p-namespace是一样的。而构造器注入还可以指定构造器中的参数位置,这个可以前缀_n来指定。例如注入第0个参数就是c:_0-ref="beanTwo",注入第1个value是c:_1="haha",这种叫做index notaion。官方推荐使用name notation,而不是index notation。
复合属性名注入
property标签进行属性注入的时候,可以直接给多层对象后的一个属性修改值。例如<property name="fred.bob.sammy" value="123" /> ,前提是前面的fred和bob对象都不为空,否则会报空指针异常。
depends-on 依赖
使用depends-on可以手动声明一些bean必须等到其他bean初始化之后才会初始化。可以是单个bean,也可以是一个用逗号分隔开的bean列表。例如<bean id="beanOne" class="ExampleBean" depends-on="manager"/>。
如果bean都是单例的(默认情况就是),则bean的销毁时间也会被depens-on影响,声明depends-on的bean会先于被依赖的bean销毁,因此说depends-on也可以用来控制bean的销毁次序。
depends-on的一个用途是:创建一个bean之前,可能需要先执行一下另一个类的静态代码,例如连接数据库之类的操作。而两个bean之间又没有明显的组合和聚合关系,就可以用depends-on来保证bean创建时,数据库已经连接好。
Bean的懒初始化
默认情况下,Bean会在ApplicationContext等IoC容器初始化的时候就被创建,这样有助于尽早发现配置中的错误。但是,也可以手动声明一个bean是lazy-initialized的。这样,这个bean只有当真正第一次被需要的时候才会创建起来。
声明的方法是在bean标签中使用lazy-init属性进行标注:<bean id="lazy" class="com.something.ExpensiveToCreateBean" lazy-init="true"/>
如果一个xml4文件中beans下面想要都是默认lazy-init的,可以直接在beans的属性中添加default-lazy-init=”true”。
注意:当一个lazy-init的bean被一个非lazy的bean依赖的时候,为了满足依赖条件,容器还是会在初始化的时候立刻创建这个bean。
自动装配 Autowiring
使用自动装配,就不再需要手动指定ref,Spring容器会自动根据Autowiring mode的设置帮我们找到合作的对象,然后自动将他注入进来。Spring中有四种Autowiring mode,可以直接配置在xml的bean的autowire属性中:
- no。默认,不使用自动装配。
- byName。只能用于属性注入。Spring寻找和属性同名的bean,装配进来。
- byType。只能用于属性注入。Spring寻找和属性类型相同的bean,装配进来。如果有多个Bean类型相同,会报错。
- constructor。和byType类似,但是用于构造器注入。如果有多个类型符合的Bean,会报错。
byType和constuctor模式中,都要求类型相同的bean仅能有一个(如果一个都没有就不会注入,也不会报错)。当注入的是一个collections的时候,有多个类型符合的就没问题,所有bean都会被注入到这个collection里面(例如List,Set等)。如果是Map,则有多少个类型匹配的,map就会有多少个键值对,键是bean的name,而值是bean的引用。
虽然自动装配很方便,不需要再手动指定装配的bean,但也有很多缺点:
- 不能装配基础类型、字符串和类类型。
- 原有的手动装配,本身具有很好的可读性,一些工具也可以据此生成文档。使用了自动装配之后这些优势不复存在。
- byType和constuctor模式无法处理有多个类型匹配的bean出现的情况。对于这一点,有一些解决方法:设置autowire-candidate属性为false,让一个bean不会被自动装配到其他bean中;使用primary=”true”属性显式指定要装配哪一个bean;使用注解实现的bean配置方案,其中有一些方法可以解决这个问题。
对于autowire-candidate=”false”方案,只适用于byType和constuctor模式这一类依靠类型匹配来装配的场景。也就是说,如果使用的是byName模式自动装配,就算设置了这个属性,bean还是可以被装配到其他bean中。
还可以在beans标签中指定default-autowire-candidates属性,来通过名称限制可以当做装配部件的bean。例如dafault-autowire-candidates=”*Repository”表示,只有Repository结尾的bean才可以当做装配部件。当然,bean标签上的autowire-candidate具有更高的优先级。
方法注入
依赖注入可以处理大多数一个对象依赖其他对象的问题,但是对于两个对象声明周期不同的情况却有些麻烦,例如一个对象A的一个方法每次都需要一个B的全新对象。一个简陋的解决方案是,让A集成ApplicationContextAware接口,就可以在A中使用容器的方法,通过getBean在方法体中手动每次获得一个新的B对象。这么做的问题.是,业务代码会和SpringFramework紧密耦合在一起,以后更换框架会非常麻烦。
于是Spring提供了“方法注入”。最常用的是Lookup Method。简单来说,A对象中可以提供一个获取B对象的方法,A中的其他方法可以调用这个方法获得B的实例。但是这个方法的实现不需要我们给出,通过配置,可以让Spring帮我们实现或者覆盖这个方法(原理是动态代理)。在A的Bean下通过<lookup-method name="createB" bean="myB">标签,告诉Spring哪一个是要覆盖的lookup method。同时,如果要实现上面的要求,B的scope要设置为prototype,表示每次获取的时候都会创建一个新的B实例,而不是默认的单例。如果没有这样做,A每次调用createB获得的都是同一个实例。或者可以使用注解@Lookup("myB")来进行lookup method注入。myB也可以不写,Spring会根据类型进行Bean匹配。
文档中介绍的另一种叫做方法替换,意思是可以把一个类的方法提供一个动态实现,让Spring去帮忙更改方法的行为。要实现方法替换,需要创建一个类实现MethodReplacer接口,将新的实现声明在reimplement方法中。之后,在Bean配置中,被更改的类下使用
<replaced-method name="methodToBeReplaced" replacer="replacementComputeValueBean">标签来告诉Spring,哪一个方法替换成哪一个实现。这个标签下面,可以使用arg-type方法来指定一些参数,来避免同名方法有多个Overload方法。如果没有歧义,就不需要声明方法参数。
Bean的作用域
首先明白为什么会有scope的概念。一个Bean的Class代码,就相当于做菜的需要的材料。例如定义一个锅的Bean:扁半球形,可以烹饪;萝卜的Bean:红色,可以煮汤等等。xml之类的配置元数据相当于菜谱。Spring容器就像一个厨师,根据Bean创建起来需要的东西,然后根据xml等配置元数据把材料放到该放的地方做好。然而,和做菜一样,一些材料是永远只需要用同一个就够了,比如锅;而有些材料是每顿饭用一个新的,比如一次性筷子;有些材料一次就会用很多新的,比如胡萝卜洋葱。这些一个Bean对象可以使用的范围,就是Bean的作用域。
Spring提供了6个scope,其中四个都和web应用场景有关:
- singleton。默认scope。每一个容器内只会有一个该bean对象。bean对象会被Spring容器缓存,每次通过id或者名字查找到这个bean,都会返回同一个共享的实例对象。
- prototype。可以有任意多个该bean对象,每次请求的时候都会提供一个新的(例如通过id查找组装,或者调用getBean方法)。需要注意的是,相比于其他scope,Spring并不会全面托管prototype的bean的完整生命周期。意味着Spring把bean对象创建起来并且组装给客户代码之后就不管了,并不会主动调用destruction回调函数,这个需要客户代码自我管理。在某种意义上,IoC容器对于prototype的bean相当于new,客户代码还是需要自己管理对象的生命周期。
- request。每次http请求会有一个自己的bean实例。
- session。一个http session会有一个bean实例。
- application。一个SevletContext独享的bean实例。
- websocket。一个WebSocket独享的bean实例。
关于singleton和prototype,对于有状态的bean对象,应该用prototype;对于无状态的bean对象,应该用singleton。
要声明一个bean的scope,要在xml中这个bean标签中声明scope="xxx",例如scope="prototype"。
如果一个singleton的bean每次需要一个新的prototype bean,不能使用常规的依赖注入的方式将prototype bean注入到它的一个属性里,因为这样的注入只会在singleton bean被创建的时候创建一次prototype的bean。有两种方法可以解决这个问题:
- 可以使用之前提到的method injection的方案。创建一个createXxx的方法,然后把这个方法交给Spring托管。之后每次调用createXxx的时候,Spring会根据被注入的bean的scope,判断是使用已有的还是新创建。
- 可以使用
<aop:scoped-proxy />来给注入内容小scope的bean创建代理对象(不许引入aop相关依赖就可以使用)。例如在一个singleton scope的bean pot中,注入生命周期为prototype的bean carrot,可以在xml配置中carrot的bean下面加上这个。原理是创建一个透明的代理对象,当调用对象的一些方法时,该代理对象根据scope判断此处要使用哪一个实例(没有会创建新实例),然后调用对应实例的方法。
request、session、application、websocket这四个scope只有在使用web-aware的ApplicationContext作为容器的时候才可以使用,例如XmlWebApplicationContext。如果使用ClassPathXmlApplicationContext这一类常规的ApplicationContext,解析xml的时候会抛出异常。有些时候,要使用这些scope还需要一些额外的配置。但是无论是使用DispatcherServlet、RequestContextListener还是RequestContextFilter,他们本质上都是把一个http请求和一个线程绑定在一起,使得设置这些scope成为可能。
Bean的性质
Spring允许我们自定义Bean的性质。
生命周期回调
init method 和 destroy method
Spring在Bean的生命周期中提供了可以接入用户自定义行为的地方,用户可以声明一些回调函数,容器就会在处理Bean的时候在特定时期触发,来实现自定义的行为。
最常用的两个回调函数就是初始化回调函数和析构回调函数。初始化回调函数会在容器将Bean的属性设置好之后执行,而析构回调函数会在Bean的容器被销毁的时候执行。
无论定义上面哪一个回调,都有三种方式:
- 让Bean的类继承Spring提供的接口,并实现接口中的方法实现。如果是定义初始化回调函数,要实现InitializingBean接口,实现其中的afterPropertiesSet方法;如果是析构回调函数,则要实现DisposableBean并实现destroy方法。缺点是对代码具有侵入性。
- 在Bean中自定义函数,然后再Bean的配置元数据中声明。例如可以xml中可以在bean标签的属性中声明
init-method="init",可以将init成员方法设置为初始化回调函数。destroy-method="cleanup"则可以在定义cleanup方法为析构回调函数。 - 使用注解,直接将想要作为初始化回调函数的方法加上
@PostConstruct,在想要作为析构回调函数的方法加上@PreDestroy注解。推荐,对代码没有侵入性。注意:使用这两个注解,在jdk11及以上版本需要额外引入外部的库:javax.annotation:javax.annotation-api:1.3.2
默认初始化和析构方法:可以在xml中配置bean的default init method和default destroy method的名字,Spring会自动查找bean类定义中对应名字的函数作为init method和destroy method。官方建议,不要对init method进行aop,因为这方法会在bean的依赖处理完后、在aop代理设置之前马上执行,这么做容易造成误会。
三种方式可以共同使用,如果每个都设置了不同的函数,则所有方法都会执行,执行先后顺序是:注解;接口的实现;xml中自定义的init method和destroy method。无论是init还是destroy都是这个顺序。就算多个配置中指定了同一个方法,这个方法也并不会被执行多次。
自定义Lifecycle
有时候bean有一些额外需要控制的生命周期需求,比如在后台开启一个守护进程。可以让Bean类实现Lifecycle接口。这个接口需要实现三个方法:start stop isRunning。当容器的start和stop方法被调用时,容器就会关联调用所有实现了Lifecycle的bean的start和stop方法。
容器实现管理所有实现Lifecycle的bean的方法是借助LifecycleProcessor,这个接口本身也是Lifecycle接口的拓展,但是提供了额外的onClose和onRefresh方法。容器默认的DefaultLifecycleProcessor的onClose会调用所有Lifecycle Bean的stop方法。对于onRefresh会稍微复杂一点。正常情况下Lifecycle只是单纯的一个规约,他有一个拓展的接口SmartLifecycle。这个接口中提供了isAutoStartup方法和stop(Callable)方法。isAutoStartup默认实现是返回true,而stop方法默认实现是调用stop()(别忘了这个无参的stop是Lifecycle中的方法),然后调用传入的回调,表示stop完成。
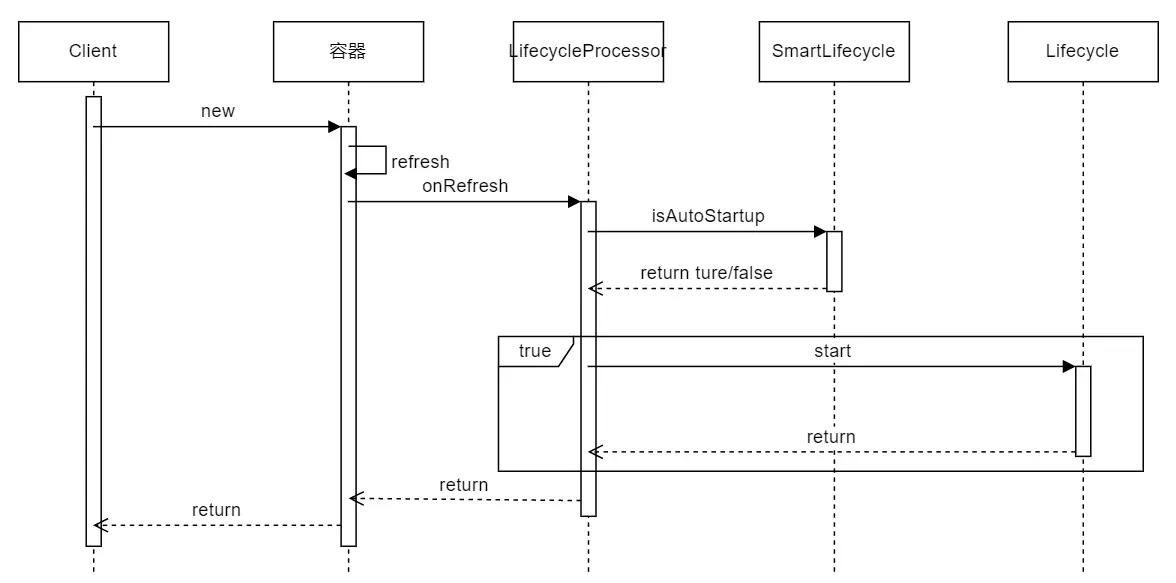
下图展示了创建容器时Lifecycle工作原理。注意:SmartLifecycle和Lifecycle应该是同一对象,这里分开是为了看清哪一个方法是哪一个接口上的。refresh方法也可以手动显式调用。
下图展示了容器关闭时的Lifecycle的工作原理。
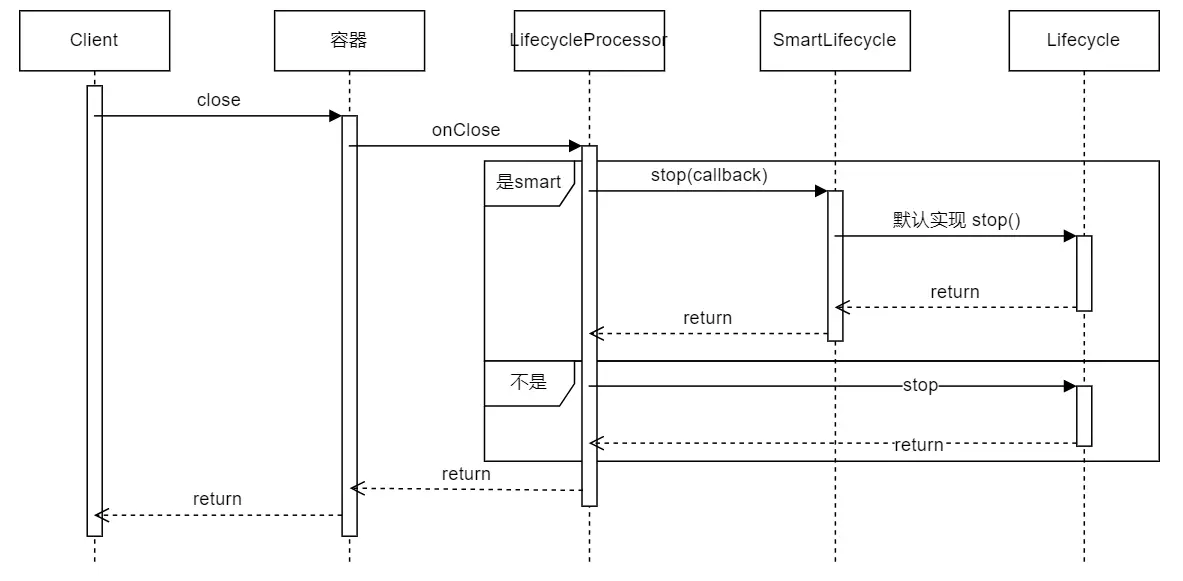
从上面两个图可知:容器close的时候会stop所有Lifecycle,但是非SmartLifecycle和不autoStartup的SmartLifecycle只能手动start开启。容器启动的时候会自动调用refresh,此时autoStartup的SmartLifecycle就会启动,同时refresh函数用户还可以手动调用。
SmartLifecycle的另一个作用是用户可以自定义每个Bean的phase(整数),类似于优先级。phase越小,容器就会越优先start它,而且越晚stop它。默认的phase值是0,对于纯Lifecycle也是如此。phase可以帮助更细粒度地按顺序启动一些服务。
优雅关闭容器:通过context.registerShutdownHook(),将关闭函数注册到虚拟机退出的时候调用。如果不这样做,虚拟机退出的时候不会关闭容器,而是直接退出,容器内的bean不会stop,无法处理后事。注册之后,虚拟机退出时会调用容器的doClose()方法,也就会stop所有的实现Lifecycle的bean,更加优雅。
Aware interface
Aware interface指的是bean可以继承一些xxxAware接口,用于感知Spring框架的存在,使用Spring容器的一些功能。例如
- 继承ApplicationContextAware,需要实现setApplicationContext方法,而这个实例被容器实例化的时候就会传入一个applicationContext,即拥有它的容器的引用。
- 继承BeanNameAware接口,需要实现setBeanName方法,Bean被容器实例化的时候会传入它在容器中的名字。这样,Bean就知道了自己在容器中叫什么。
还有其他各种Aware,旨在让Bean知道自己处在什么环境下。没有Aware的Bean实例就好像柏拉图的洞穴寓言,Aware不知道自己在被谁操纵。而继承了Aware接口,Bean就拥有了神明般的能力,可以感知自己的上帝(至少一部分)。这样做总的来说是不推荐的,会给Bean暴露各种各样的环境信息,将Bean的代码和context耦合在一起,破坏控制反转的风格。
Bean继承
在Bean的配置元数据中,可以让一个Bean的定义继承另一个Bean(xml中通过parent=“xxx”实现),实现类似Java继承的父子关系。
子Bean会默认从父bean那里继承scope、构造函数参数、属性、方法的覆盖。子类还可以覆盖父类相关的配置。
一个比较重要的bean标签属性是abstract=”true”。如果定义了这个属性,就类似声明了一个抽象类。这个bean本身不能被实例化,他的id也不能被ref引用,不能通过getBean获得,否则会报错。这样可以把bean定义的用途限制在被其他子Bean实现上。如果bean的class没有写,就必须要声明为abstract的。
容器行为拓展
有时候我们希望改变一下容器的行为,更方便地定制化管理其中的bean。一种方法是自己手写一个ApplicationContext的实现类,实现自己的容器。当然这样做太麻烦了,我们也可以通过给现有的容器插入一些特有接口的实现类,来改变一部分容器的行为。
BeanPostProcessor
BeanPostProcessor接口中会定义一些列回调函数,用于管理容器的初始化逻辑、依赖处理逻辑等等。如果用户想在Spring原有容器的基础上加上一些额外的动作,可以插入多个自定义的BeanPostProcessor。另外,如果自己实现的BeanPostProcessor同时实现Ordered接口,还可以指定多个Processor的先后顺序。
注意:BeanPostProcessor的作用域是一个容器。就算容器之前就等级关系,一个容器内的Processor也不会影响到其他容器。如果想要自定义Bean配置元数据的写法,不应该使用BeanPostProcessor,而是使用BeanFactoryPostProcessor。BeanPostProcessor提供两个回调函数,分别会在容器对Bean进行初始化之前和之后调用。通常可以做一些接口检查,以及做一些动态代理的包装。
BeanPostProcessor本身插入的容器中的方式,也是和其他Bean一样,只不过容器会自动识别实现了BeanPostProcessor的bean,注册到自己的BeanPostProcessor里面,这也是比较推荐的做法。使用这种方法不需要为这个bean指定id或者name。除此之外,还可以通过容器的addBeanPostProcessor方法代码式添加BeanPostProcessor,这种做法注册的processor总是比自动识别的processor执行更早。
BeanPostProcessor和AOP自动代理的关系:AOP自动代理本身也是BeanPostProcessor实现,所以BeanPostProcessor的bean并不能使用自动代理。除此之外,如果BeanPostProcessor的bean中依赖了一些其他bean,导致容器需要按照类型查找匹配他们,这些查找过程中设计的可能类型的bean都不能使用自动代理和一些BeanPostProcessor。
BeanFactoryPostProcessor
和BeanPostprocessor其他性质非常相似,本身也是作为bean放在容器中被自动识别,也可以实现Ordered接口进行顺序指定。只不过,BeanFactoryPostProcessor做的事情是对Bean配置元数据进行预处理,作用类似于宏的感觉。
常用的两个Spring提供的BeanFactoryPostProcessor有:PropertySourcesPlaceholderConfigurer和PropertyOverrideConfigurer。
PropertySourcesPlaceholderConfigurer用来根据额外的Properties配置文件,替换掉bean配置元数据中的占位符(类似于class="${custom.strategy.class}"这样的内容)。可以使用类似如下bean定义来使用。<bean class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer"> <property name="locations" value="classpath:com/something/jdbc.properties"/> </bean>常用的场景是允许根据配置文件切换某个bean的具体实现类。
在Spring 2.5之后,可以使用简化写法:
<context:property-placeholder location="classpath:com/something/jdbc.properties"/>PropertyOverrideConfigurer用来覆盖原来的配置元数据,相比于上者,它还能覆盖不含占位符的配置,以及新建没出现过的字符。使用类似如下bean定义来使用:<bean class="org.springframework.context.support.PropertySourcesPlaceholderConfigurer"> <property name="locations" value="classpath:com/something/jdbc.properties"/> </bean>Spring2.5之后也有了相应的简化写法:
<context:property-override location="classpath:override.properties"/>
FactoryBean
实现这个接口可以自定义容器初始化Bean的逻辑。实现这个接口需要三个方法:
- T getObject() 初始化和创建bean的方法。
- boolean isSingleton() 用于描述这里创建的是不是单例。
- Class<?> getObjectType() 用于返回Bean的类型。
在使用context.getBean()方法的时候,如果指定的id是一个FactoryBean,默认会返回这个FactoryBean的产物;如果想获得这个FactoryBean本身,则要在id前面加一个&符号。
注解配置
可以使用注解方式代替xml配置文件来配置bean。两种方式各有优缺点:基于注解会更加清晰好写,但是基于xml会使得配置更为集中方便管理,而且完全不需要修改原有的代码。关于修改原有代码这一点上,Spring还提供了一种基于注解配置但不需要修改原有的java文件的方法。
有一点需要注意的是:基于注解的配置会比xml提前生效,因此xml配置可能覆盖掉注解中的属性值。
如果要使用注解配置,需要在xml文件中声明<context:annotation-config/>,它会为容器引入一些列注解处理相关的BeanPostProcessor,来正确处理代码中的注解。
@Required在5.1版本正式过时,这里不再提及。
@Autowired
基本用法
该注解的几种使用方法:
- 这个注解可以放在构造器上,表示让容器使用这个构造器,按照类型匹配构造器中的参数来将所有依赖自动装配进来。如果只有一个构造器,则这个注解可以省略,因为这个构造器是一定会执行并Autowired的。
- 还可以放在setter方法上,自动装配一个属性。
- 也可以直接加在属性名上进行setter注入形式的自动装配。另外Autowired写在属性上甚至不需要这个属性有setter方法就可以成功注入,但是使用xml给没有setter的private属性注入却会报错。
- 放在属性和放在构造器上的可以都混合使用。
- 还可以放在任意的方法上,在初始化阶段,容器会自动执行这个方法,并且为每个参数进行自动装配。事实上,这样的方法也可以有很多个,Autowired使用的数量是不限制的。
- 还可以使用一个集合,让Spring自动装配所有符合类型的bean到这个集合中,称为multi-element injection points。注意:如果是List这样有顺序的集合,可以通过三种手段指定这种聚合到集合的时候bean的先后顺序:实现org.springframework.core.Ordered接口;使用@Order或者@Priority注解。如果是一个Map,则key需要是String类型的,这样容器会把所有的类型匹配的bean自动装配,同时将bean的名称作为key放入Map。如果没有任何一个类型匹配的bean,自动装配会失败。
required属性
required的意义在于,在一些属性或方法因为缺少bean无法注入时,不会报错而是会直接忽略不执行。
默认情况下,使用@Autowired进行自动装配,意味着会在两个类直接形成depends-on的依赖关系,会影响到bean的初始化顺序。如果不想让自动装配绑定依赖关系,可以使用@Autowired(required = false)。当使用non-required的Autowired的时候,如果是在方法上,假如方法中的参数没有相应的Bean定义,这个方法就不会被执行(如果是默认required的话会报错);如果是在属性上,没有相应的Bean定义的话,相应的属性会保持初始值,并不会被注入。注意,这里关注的是没有Bean定义,而不是相应的Bean有没有创建。
对于集合类属性(或者构造器参数,称为multi-element injection points),假如没有类型匹配的bean,会可能有不同的表现:
| 出现位置 | required=”true” | required=”false” |
|---|---|---|
| 属性 | 报错 | 保持默认值(多数为null) |
| 构造器或工厂方法 | 可以注入,但是空集合 | 可以注入,但是是空集合 |
required和构造器:
- 只有一个构造器的时候,这个构造器上的Autowired可以省略,也就是说唯一的构造器会被直接当做required Autowired处理。
- 如果只有一个构造器有Autowired,即使构造器上标注了是non-required的Autowired,这个构造器还是会被当做effectively required 即事实required,效果等同于required。这是因为,唯一一个构造器的执行是不可避免的!
- 所有构造器中,只能有一个是required的Autowired。当有多个构造器都有Autowired的时,必须都是required=”false”的,如果其中有false有true会报错。当有多个构造器是non-required Autowired时,容器会选择能满足的、匹配参数最多的构造器,效果和xml中声明bean的autowire=”constructor”效果一样。
其实,关于构造器,可以这样去理解:容器初始化Bean,一定需要一个合适的构造器,如果没有合适的构造器就会报错。当引入了<context:annotation-config/>之后,容器使用构造器的时候,就一定会给所用的构造器传入参数,因此一定会有Autowired的过程。有多个构造器的时候,Spring会将required Autowired注解的构造器视为指定构造器,而non-required Autowired的构造器视为候选构造器,因为创建对象只能使用一个构造器,因此required Autowired的构造器不能有两个,也不能有了指定的构造器之后,还有候选的构造器。如果都是候选构造器,容器会选择可用且匹配最高的构造器来使用。
由于容器通过反射来执行构造,因此无视构造器的可见性是不是public。但是如果同时存在public和private的构造器,总是会优先使用public的构造器,没有合适的public的构造器,再使用private构造器。
Optional参数和@Nullable参数
如果进行Autowired的方法(包括构造器)中,有Optional参数或@Nullable注解的参数,则这个参数允许不存在相应的bean,容器执行方法的时候会为它的位置填入null。
其他
BeanFactory, ApplicationContext, Environment, ResourceLoader, ApplicationEventPublisher, and MessageSource这些熟知类型的bean可以直接被自动装配,不需要自己声明。
由于注解本身是由BeanPostProcessor处理的,因此在自定义的BeanPostProcessor中不能使用注解来自动注入依赖,如果有需要只能使用xml来自动注入。
@Primary
primary注解用于自动装配场景,指定哪一个bean将作为依赖装配到其他bean。在自动装配的时候,如果有多个类型匹配的bean,primary的bean会被选中(要求只有一个primary)。Primary可以放在生成bean的工厂方法上,也可以放在类上。
还可以在xml配置中,在bean标签中使用primary=”true”属性来指定这个bean为primary。
@Qualifier
用于筛选多个类型匹配的bean,找到最合适的进行自动装配。
可以在属性或构造器参数等需要自动装配的地方指定qualifier,容器会自动选择类型匹配具有相同qualifier的bean进行装配。
如果注入点是集合,也可以容纳多个qualifier匹配的bean,qualifier可以理解为一个过滤器。
如果bean没有指定qualifier,它的默认qualifier是id。
使用注解的场景下,如果有多个类型匹配,就算没有primary和qualifier消除歧义,容器还有最后一招,就是找和注入点同名的bean,如果有这样的bean,还是可以注入成功的。但是不推荐
可以自定义自己的qualifier注解,如果注解中只有一个String类型的变量,则可以类似于Qualifier一样使用,用value表示这个变量内容,同时用type指定自定义注解的类型。如果有多个变量(可以是枚举值,则要在xml中使用attribute子标签来指定每一个变量的值,只有所有变量都匹配才会筛选成功。
如果想使用byName的自动装配,更推荐使用@Resource注解,而不是基于Qualifier做匹配。使用@Resource可以忽略类型匹配,完全从bean的名称考虑匹配。
泛型
可以使用泛型中的类型(尖括号中的)来过滤候选的bean。例如,一个属性接受ArrayList<String>类型的bean,那么ArrayList<String>类型的bean就会被采用,而不会采用ArrayList<Integer>类型的bean。
@Resource
@Resource用来代替@Autowired,虽然也有自动装配的作用,但是优先使用按名称来匹配。可以使用@Resource(name="xxx")表在属性或者setter方法上来将名字为xxx的bean注入进来。如果在注解上不指定name,会自动采用属性的名字或者setter方法中提取出的属性名字来匹配。
按照名字查找没有找到相应的bean时,才会再尝试按照类型进行匹配。此时又退化成@Autowired的逻辑,像一些熟知的bean也可以直接被装配进来。
@Value
用于将一些外部变量的值注入进来,起到的作用和xml中属性标签的value属性类似。
使用的语法类似@Value("${catalog.name}")。这个catalog.name是从外部的properties文件中加载的。为了让容器能够正常加载,还需要再xml中配置一个PropertyPlaceholderConfigurer的bean(参考之前的BeanFactoryPostProcessor中的例子),或者使用@Configuration和@PropertySource(“classpath:application.properties”)类似的注解配置一个bean。
默认没找到这个属性的时候,会将文本按照原样注入,例如上面的例子中会直接注入${catalog.name}。如果要对没找到的情况进行检查,可以在声明一个PropertySourcesPlaceholderConfigurer的bean,实现没找到属性的时候报错,而不是注入带有占位符的字符串。
底层上,Spring容器中的ConversionService(一个BeanPostProcessor)会帮我们做一些简单的类型转换的工作,例如把文本中的整数转为真正的整数,把文本中的字符串转为String类型对象等。我们也可以通过给默认的ConversionService对象调用addConverter来添加自己的类型转换逻辑。
使用SpEL还可以再@Value的字符串中写一些表达式计算,容器会自动解析,然后将结果注入。SpEL相关内容后面有详细的说明。

