




what is glusterfs
glusterfs 是一个分布式文件存储系统,可以将多台机器的存储资源整合在一起,抽象成新的逻辑存储卷供用户使用。
下图是glusterfs的形象化描述:
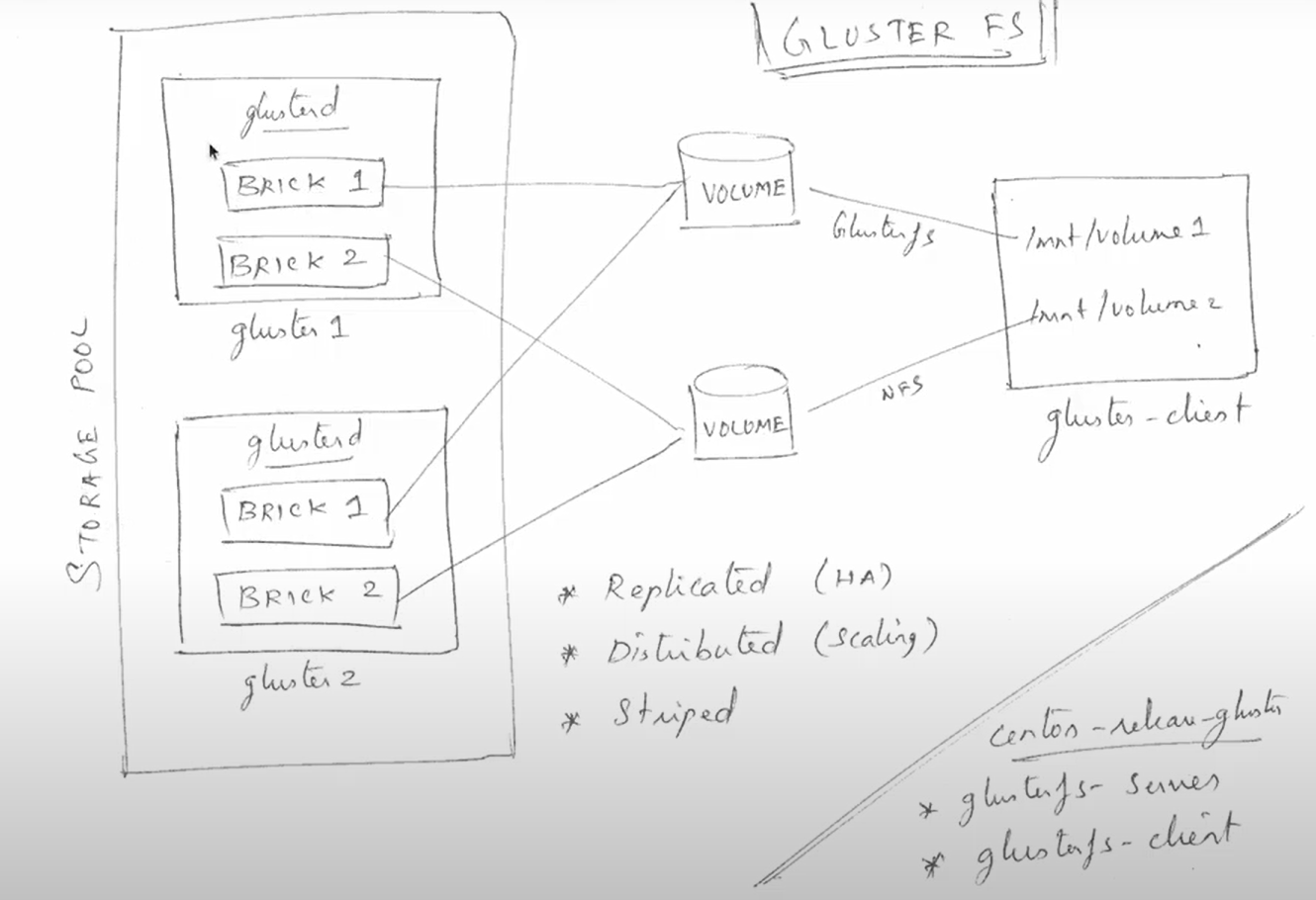
如图,glusterfs不存在“中心节点”或者“master节点”的概念,而是所有参与构成的节点共同构成一个storage pool。其中,不同的节点上可以建立若干个brick,然后brick组合,构成volume。构成一个逻辑卷volume的brick可以有不同的协作方式,最典型的有replicated和distributed。replicated的volume的brick之间互为备份,因此具有高可用性(HA high accessablility),不会因为某一节点挂掉而影响资源访问。distributed模式中,volume的brick之间互相扩展,所有brick组合,容量比单个节点更大,而且可以非常方便地加入新节点拓展(scaling)容量。
以上是gluster-server完成的工作,构建起分布式文件系统。访问这个分布式文件系统需要配合glusterfs-client。通过glusterfs-client可以直接将gluster上的volume挂载到本地进行使用,非常便利。
glusterfs的安装
ubuntu
apt install glusterfs-server
附带glusterfs-client一同安装好。
centos
先安装glusterfs的yum仓库:
yum install -y centos-release-gluster
然后就可以安装glusterfs-server了。
yum install glusterfs-server
也会附带安装client等一系列套件。
匹配节点
gluster pool list 列出 storage pool中所有节点
gluster peer status 列出匹配的节点状态
gluster peer probe <hostname/ip> 向storage pool中添加节点
gluster peer detach <hostname/ip> 从storage pool中删除节点,前提是要删除的节点目前没有参与构成volume。如果有,需要先将对应的volume全部删除才可以删除节点。
配置数据卷
创建数据卷
创建replicated模式的数据卷:
gluster volume create <volumename> replica <2> <gluster1:/gluster/brick1> <gluster2:/gluster/brick1> <force>
glusterfs推荐的备份数量最好是奇数个,因此配置为偶数时会有warning。glusterfs还建议使用新的磁盘分区作为brick的存储区域,而不是使用安装有操作系统的分区,如果一定要这么做,要在最后加上force,才能创建成功。
创建distributed模式的数据卷:
gluster volume create <volumename> <gluster1:/gluster/brick2> <gluster2:/gluster/brick2> <force>
glusterfs不指定模式时,默认创建的就是distributed模式的数据卷。
创建完成volume后,要start才能使用:
gluster volume start <volumename>
挂载数据卷
之后,就可以在安装有glusterfs-cli的机器上通过mount挂载gluster volume进行使用:
mount -t glusterfs <gluster1:volume1> </mnt/gluster_test>
查看是否挂载成功:
mount | grep <volume1>
如果volume不再使用,先卸载:
umount /mnt/gluster_test
拓展数据卷
gluster volume add-brick <volume1> <gluster2:/gluster/brick1> 用来向volume中增加brick。
增加了新的brick之后,还不会立即将之前的文件存入该brick,可以通过rebalance命令将文件重新平衡到所有brick中:
gluster volume rebalance <volume1> start 启动rebalance进程。等待rebalance完成后可以使用gluster volume rebalance <volume1> status 命令来查看rebalance的状态(转移文件数等)
压缩数据卷
和拓展数据卷时的操作相反,想要从一个storage pool中移出一个brick的时候,需要将该brick的文件分配到其他brick,然后再移出。命令上也分为两步操作:
首先:
gluster volume remove-brick <volume1> <gluster2:/gluster/brick1> start
这一步会将要移出的brick中的文件平衡到其他的brick中。
最后:
gluster volume remove-brick <volume1> <gluster2:/gluster/brick1> commit 将该brick移出。
中间,可以使用
gluster volume remove-brick <volume1> <gluster2:/gluster/brick1> status 查看移出操作的状态。
数据卷选项
gluster volume get <volume1> all 可以查看一个volume的所有配置项。也可以指定具体的配置项名称进行查看,例如gluster volume get <volume1> auth.allow
gluster volume set <volume1> auth.reject gluster-client,127.0.0.1 可以设置不允许连接gluster的地址。
gluster volume reset <volume1> auth.reject 可以重置某选项。
可以在/var/log/gluster中查看日志,其中bricks的目录中保存了具体brick的日志。
删除数据卷
然后停用volume:
gluster volume stop <volume1>
最后删除volume:
gluster volume delete <volume1>
删除volume后,已经储存在brick中的数据还在,并不会随之删除。如果需要还要手动删除。
volume配额
可以指定配额限制volume的使用。
gluster volume quota <volume1> enable 启动配额。volume必须已经创建并启动。
gluster volume quota <volume1> limit-usage / 20MB 限制volume根目录的使用量为20M。不仅可以设置整个volume的配额,还可以设置某个子目录的配额限制。
使用heketi管理glusterfs cluster
安装配置heketi
下载heketi
{
cd /tmp
wget https://github.com/heketi/heketi/releases/download/v10.1.0/heketi-v10.1.0.linux.amd64.tar.gz
tar zxf heketi*
mv heketi/{heketi,heketi-cli} /usr/local/bin/
}
设置账户
{
groupadd -r heketi
useradd -r -s /sbin/nologin -g heketi heketi
mkdir {/var/lib,/etc,/var/log}/heketi
}
设置密钥访问gluster node
{
ssh-keygen -f /etc/heketi/heketi_key -t rsa -N ''
for node in gluster-1 gluster-2; do
ssh-copy-id -i /etc/heketi/heketi_key.pub root@$node
done
}
配置heketi
cp /tmp/heketi/heketi.json /etc/heketi/
修改配置文件json,修改user_auth和executor:
"use_auth": true,
"_jwt": "Private keys for access",
"jwt": {
"_admin": "Admin has access to all APIs",
"admin": {
"_key_comment": "Set the admin key in the next line",
"key": "secretpassword"
},
"_user": "User only has access to /volumes endpoint",
"user": {
"_key_comment": "Set the user key in the next line",
"key": "secretpassword"
}
…………
"executor": "ssh",
"_sshexec_comment": "SSH username and private key file information",
"sshexec": {
"keyfile": "/etc/heketi/heketi_key",
"user": "root",
"port": "22",
"fstab": "/etc/fstab"
其余不需要的内容也记得删除,例如ssh下面的其他含有注释说明的配置,以及kubenetes相关的示例配置。
运行heketi服务
首先赋予用户权限
chown -R heketi:heketi {/var/lib,/etc,/var/log}/heketi
然后创建服务:
cat <<EOF >/etc/systemd/system/heketi.service
[Unit]
Description=Heketi Server
[Service]
Type=simple
WorkingDirectory=/var/lib/heketi
EnvironmentFile=-/etc/heketi/heketi.env
User=heketi
ExecStart=/usr/local/bin/heketi --config=/etc/heketi/heketi.json
Restart=on-failure
StandardOutput=syslog
StandardError=syslog
[Install]
WantedBy=multi-user.target
EOF
最后启动服务并设置开机自启:
{
systemctl daemon-reload
systemctl enable --now heketi
}
测试连通性:
curl localhost:8080/hello; echo
如果需要在本机使用,则可以将heketi的用户名和密码这些验证信息设置到环境变量中使用:
export HEKETI_CLI_USER=admin
export HEKETI_CLI_KEY=secretpassword
使用heketi管理gluster集群
heketi中有五个概念:
- cluster 集群
- zone 类似故障域,heketi会尽量将数据冗余到不同的zone提高容错率
- node 主机节点
- device node上的一个可以用来存储数据的分区
- volume 卷
首先创建cluster:
heketi-cli cluster create
列出cluster:
heketi-cli cluster list
查看cluster信息:
heketi-cli cluster info <cluster-id>
向cluster插入node:
heketi-cli node add --zone=1 --cluster=<cluster_id> --management-host-name=xxx --storage-host-name=xxx
查看所有node列表:
heketi-cli node list
查看node信息:
heketi-cli node info <node-id>
给node添加device:
heketi-cli device add --name </dev/sdc> --node <node-id>
创建volume:
heketi-cli volume create --size=1 --replica=2
只需要告诉heketi希望有多少冗余备份即可,heketi会自动选取最佳的存储方案,创建brick和volume。
如果只有一个节点的话,需要--durability=none,然后不指定replica,否则会报Error: Failed to allocate new volume: No space错误,例如heketi-cli volume create --durability=none --size=10
查看所有volume列表:
heketi-cli volume list
查看volume的信息:
heketi-cli volume info <volume-id>
可以看到挂载点名称,使用这个名称就可以将volume挂载到自己的主机上了。 注意,信息中有mount options,也要在挂载的时候用上,就可以挂载点的主机掉线导致挂载失败了。例如:
mount -t glusterfs -o <Mount Options> <Mount> </mnt>

