




函数
C++中的函数不可嵌套定义,必须先定义后使用(定义即签名,和具体的函数内容分开)。
函数执行在栈中进行。函数的参数传递包括值传递和引用传递两种。调用函数时,需要保存调用者的状态,然后将控制转交给被调用函数。
函数调用步骤:
- push参数
- push eip中的代码区返回地址,以及数据区的基址寄存器。
- 执行函数:设置栈底指针、分配空间、运行代码、释放空间
- 恢复栈顶和栈底到调用者的状态
- 恢复eip到调用者的下一条命令地址,继续执行调用者函数
栈中执行
程序执行时使用到的内存可以分为代码区、数据区、栈、堆。在Code区存放函数的代码,因此函数也可以按照地址来访问,也就是函数指针的原理。编译器在编译时会生成一个符号表,存储变量和函数的标识符和对应的位置。C++中支持函数重载,因为符号表中不仅记录了函数名,而且记录了返回值和参数列表。
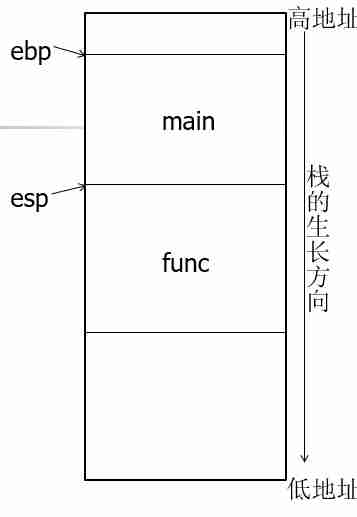
函数的执行是在栈中进行的。计算机中两个特殊用途的寄存器:ebp用来记录栈底的地址,而esp用来记录栈顶的地址。栈的生长方向是从高地址向低地址。如下图所示:
参数传递
调用函数时,会在栈中向下使用一块空间存储参数,这块空间作为调用函数和被调用函数都能访问的空间,协助完成参数传递。
这也意味着,调用函数之前必须看到函数的原型(签名),这样才知道如何为参数传递分配空间。
如果是引用传递的话可以传入一个变量的引用,实际上是把一个变量的控制权交给了被调用函数。
在栈中完成参数传递的时候,参数保存在调用者的空间中。这种方法可能会造成空间的浪费,但是支持了可变数量参数的传递。
函数原型
遵循先定义后使用的原则,如果调用前写明函数原型,那么函数具体的定义就可以自由安排。函数原型的声明中,只需要参数的类型而不需要指定参数名,编译器只会检查参数类型。
函数原型的存在使得递归调用成为可能。
函数原型:Declaration;函数定义:Definition。
函数重载
函数重载体现了多态。
函数重载要求名同而参数不同(个数、类型、顺序中至少有一个不同),返回值的类型不作为区别重载函数的依据。
当调用重载函数的时候,如果参数类型不能精确匹配,那么编译器会尝试进行默认的类型转换。但是如果此时发现有多个可能转换到的重载函数版本,就会报错。例如,下面的代码是不能通过编译的。
void foo(long);
void foo(double n);
int main() {
foo(10);
return 0;
}
void foo(long n){
cout<<"long "<<n;
}
void foo(double n) {
cout<<"double "<<n;
}
另外,由于C中不支持函数重载,而C++中支持,因此,如果想使用C中的某个重名函数,需要用extern "C"放前面来指定调用C中该函数版本(C和C++混合编程时使用)。
默认参数
提前设置好一部分参数的取值,这样不必每次都传入所有参数值。
默认参数的声明必须且只能在函数原型中给出。定义时指定的默认参数没有意义。默认参数声明时,必须放在非默认参数的后面。
使用默认参数时,会将参数列表中的值从左往右依次分配给函数原型中的参数,不能跳过前面的默认参数直接给后面的默认参数赋值。
内联函数
函数调用会进行参数传递等一系列动作,产生代价。对于那些非常简单的函数,可以通过声明成内联函数的方法避免这些代价。内联函数实际上在编译时代码会被拷贝到调用者的代码中去,运行时并不进行函数调用。这样在提高可读性的同时提高了程序效率。
通过inline关键字放在函数定义的前面可以建议编译器将函数按照内联函数编译。但是如果函数过于复杂,或者包含麻烦的循环,有可能会被编译器驳回。因此只建议将简单、小段而且使用频率高的代码做成内联函数。
在OO中,构造函数一般来说很简单而且大量使用,因此会被默认做成内联函数。
内联函数的代价是:增加了代码的长度,使得代码中散落大量重复代码,而且降低了Cache的效率。所以内联函数使用应当慎重。
const关键字
对于普通的函数来说,const关键字可以修饰参数或者返回值,有以下作用:
- 修饰参数时,如果参数是值传递的变量,则这个变量内容在函数中不能改变。如果是引用,则引用的对象不能在函数中被修改。如果是指针,则分为常量指针和指针常量的情况,常量指针表示指针指向的内容不能被函数修改,指针常量值得是指针指向的地址位置不能被修改。
- 修饰返回值时,如果返回值是指针或者引用,则必须由一个常量指针或者引用接受返回值,返回值指向的内容在外部不能被修改。例如
const char * GetString(void);函数,在调用时使用char *str = GetString();是错误的,而应使用const char *str = GetString();。如果返回值是值传递出来的,const没有任何意义。
返回值
函数的返回值如果是右值,则通常是一个栈中没有名字的临时变量。这个临时变量生存期很短,基本上都会在调用函数的语句执行之后就销毁掉。但是如果使用常量引用或者常量指针去指向这个临时值,则可以将这个临时值的生存周期延长到引用或指针销毁。注意,指针或者引用必须用const声明!
除此之外,临时变量还经常出现在类型转换的中间产物中。
下面是一个例子:
class Foo{
int i;
public:
Foo(int i) : i(i) {
cout<<"constructor"<<endl;
}
Foo(const Foo& f): i(f.i){
cout<<"copy"<<endl;
}
~Foo(){
cout<<"destroy"<<endl;
}
};
// 隐式调用构造函数
Foo getFoo(int i){return i;}
int main(){
getFoo(1);
cout<<"over"<<endl;
const Foo& foo=getFoo(1);//正确
Foo& f=getFoo(1);//错误,不能用非常量引用指向临时变量
cout<<"over"<<endl;
}
//输出为:
//constructor
//destroy
//over
//constructor
//over
//destroy
//如果将getFoo(1);改为 Foo fooo(getFoo(1)),则输出会改变为:
//constructor
//over
//constructor
//over
//destroy
//destroy
//推测原因是Cpp对返回值的值传递进行了优化,省出了一次拷贝构造
需要注意的是,返回值中没有写引用的函数,返回值都是右值,即返回的是“内存中的一块内容”,而非“一个明确的内存地址”。这块内容是临时变量,马上要随着函数退栈而回收,回收后再对该位置的内容进行修改会出现问题。Cpp中不允许非常量引用初始化为右值(因为引用的本质是变量的别名,其实就是内存地址的复制,必须现有明确的内存地址才可以复制)。
返回值也可以是左值,这个时候通常是以引用的形式返回的。例如:
int &getInt() { return *(new int(0)); }
int main() {
int &i = (++getInt());//这里使用前置的自加操作,把背后的int加上1,同时返回一个左值给引用初始化
cout<<i;
}
