




事务
数据库事务
如果没有事务的概念,没有操作的隔离,那么有可能会出现以下的错误:
- 读取可能出现不一致的结果。
- 执行冲突,并发时错误,比如多个更新操作混杂在一起时。
- 不确定数据究竟何时被持久化,可能由于系统的崩溃造成部分数据丢失带来麻烦。
事务:一系列数据库操作,要么全部生效,要么全部失效回滚,并且进行过程中不能与其他的事务发生冲突。
事务遵循以下ACID原则:
- Atomicity 原子性,一个事务的所有操作只有全部执行或者全部不执行两个选择,不可拆分执行一部分。全部执行完成要
commit,而中途执行停止则要rollback,回滚到执行前的状态。 - Consistency 一致性,一个事务结束后,所以数据的状态都一致。比方说一个转账的事务,执行前A和B账户都是初始状态,执行完后A和B的状态都是转账后的状态,不会一个是转账后状态而另一个还是初始状态。
- Isolation 隔离性,事务并发执行时,每个事务所做的修改不能影响到其他事务正常执行。
- Durability 持久性,事务执行完后,数据被持久化;即使执行过程中系统崩溃,也能够根据记录进行恢复。
串行调度和可串行化调度
串行调度即:所以事务一个接一个执行,在执行时间上没有丝毫重合。前一个事务完全完成后,后一个事务才开始执行。
串行调度强有力地保证了事务之间相互隔离的原则,但是串行调度由于CPU没有时刻工作,降低了系统的效率。因此有时候将一些不会造成冲突的事务动作穿插执行,以提高CPU效率的方式也是可取的。
可串行化调度:事务的执行并不一定严格遵守串行调度,但是由于动作顺序安排妥当,不会产生冲突和异常,看起来就如串行调度一样可靠。这种方法需要调度器进行一定的控制和判断,但是大大提高了CPU利用率。
冲突动作
事务的动作总的来说可以分为读R和写W两种。一个事务i,可以把它看成一系列读写操作的有序进行:Ri(A)表示i事务中一个对A数据的读动作,Wi(A)表示i事务中一个对A数据的写动作,那么事务i就可以表示为类似Ri(A),Ri(B),Wi(B),Wi(A)……这样的一系列动作。
一个可串行化调度中的冲突动作是指:两个事务并发时,需要严格按照顺序执行而不能互换顺序的两个分属不同事务的动作,就是冲突动作。假如互换冲突动作的顺序,就有可能造成读出或者写入的数据与严格串行调度执行时的期望不符合,也就是破坏了事务之间的隔离性原则。
当两个事务i和j并发执行的时候,他们各有一个动作Xi(A)和Yj(B),如果满足以下三个条件,那么说这两个动作是冲突动作:
- A和B是同一个数据对象,即A≌B,两个动作操作的对象相同
- i≠j,即分属两个事务(同一事务的动作必定不能交叉顺序)
- 其中至少一个为写操作
所以有三种组合的动作是冲突的:
- Ri(A) -> Wj(A)
- Wi(A) -> Rj(A)
- Wi(A) -> Wj(A)
可以看出,这三个动作的顺序都是不能互换的。比方说i事务有一个动作是读取余额,而j事务有一个动作是给余额+10,假设本来是先i再j,那么一旦j的写动作被安排到i的读动作前面就会出问题,i读到的余额就不是当时真实的余额了。也就是说出现这样的冲突动作对,调度器就需要注意要严格保证这些动作的执行顺序。如果有必要,调度器还可以暂定某个事务,避免冲突。
如果一连串动作中,通过冲突动作对的推测得到了两种事务的串行调度顺序,这样的矛盾就决定了这个动作序列不是一个可串行化调度。例如R2(A)->W2(A)->R1(A)->R1(B)->R2(B)->W2(B)->C1->C2,C1和C2表示commit。这里通过W2(A)在R1(A)之前推测出2事务必定在1事务之前执行,但又从R1(B)在W2(B)之前推测出1事务必定在2事务之前执行,产生了矛盾的结果,所以这不是一个可串行化调度,这样的调度执行起来会出现问题。
前驱图
如果已经有一个动作序列(称之为经历H),我们可以通过冲突动作对,来判断一些那些动作必须在另外一些动作前面执行。这样,把每个动作视为一个节点,用有向的边表示一个动作是另一个动作的前驱条件,就可以画出一幅动作的有向图,称为动作序列的前驱图。
通过来看前驱图,就能知道这个序列是不是一个可串行化调度:
可串行化调度定理——一个经历H可串行化的充要条件是,其前驱图中没有环。
锁机制
锁机制是一种保证事务并发执行时,一定是可串行化的一种机制。他的原理很简单:当一个事务访问数据时,必须先获得被访问数据对象上的封锁。
封锁的类型也有两种:
- 排它锁,又称为X锁或者写封锁(WL)。数据对象没有被其他任何事务加任何锁的时候,当前事务才能加排它锁,而且在当前事务仍持有排它锁的时候,其他事务不能对这个数据对象加任何锁。换句话说,一个数据对象同时只能被一个事务更改,而且更改期间不能被其他事务读取和更改。
- 共享锁,又称为S锁或者读封锁(RL)。数据对象没被加X锁的时候,任何事务都可以加S锁。但是一旦加了S锁,意味着不能有对象加X锁了。换句话说,一个对象可以同时被很多事务读取,但不能在被读取的同时被写入。
锁相容矩阵,表示一个数据对象上什么状态下允许加什么锁:
| 事务申请的锁 | 已有X锁状态时 | 已有S锁状态时 | 没有任何锁状态时 |
|---|---|---|---|
| X锁 | 否 | 否 | 可 |
| S锁 | 否 | 可 | 可 |
两阶段锁协议
一个事务T在访问A数据对象时申请封锁,完成访问后释放封锁,那么称之为一个合适事务。
两阶段锁协议(简称为2PL协议)规定了,事务对锁的操作被明确地划分为两个阶段。先是增长阶段(又称申请阶段),这个阶段中事务根据需求申请锁,同时也可以执行动作。然后是收缩阶段(又称释放阶段),事务释放所有锁。由于申请阶段和释放阶段严格隔开,所以不允许释放阶段开始之后事务又申请锁。
死锁:两个事务执行的过程中,互相持有对方所需访问数据的写锁。这样一来双方都陷入等待造成死锁,调度器必须异常终止其中一个事务,以使得能够继续进行下去。
定理:如果一个经历符合2PL,则一定可串行化。
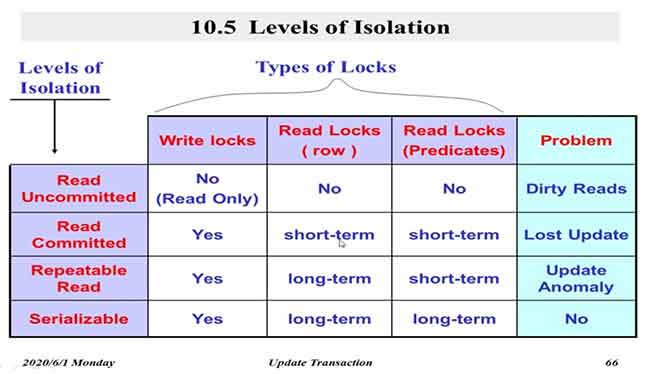
隔离级别:每个事务可以设置自己的隔离级别:
- read uncomitted 未提交读。读数据时不申请锁,但是这样的事务不允许写。
- read committed 提交读。读数据时申请读锁,读完马上释放。
- read repeatable 可重复读。读时申请读锁,直到事务结束时释放。
- serializable 可串行化。保证事务可串行化,是最高的隔离界别。
无论哪个级别(1除外),写数据时都会申请写锁并且直到事务结束释放。
日志
日志储存的内容可分为两种:
- before-image 前镜像,描述之前的一个稳定、一致状态的磁盘存储是什么样的。所以日志中会备份未提交事务的磁盘更新记录,这些记录应该是不应出现的。记录的是更新前的值。
- after-image 后镜像,描述应该出现的一个稳定、一直状态的磁盘存储。所以日志中会备份已经提交事务没有持久化的数据更改,这些更改应当被持久化。记录的是更新后的值。
所以根据上面两种记录的方式,产生了三种日志类型:
- undo logs:根据before-image的记录,恢复到未提交事务还没进行时的磁盘状态
- redo logs: 根据after-image的记录,恢复到已提交事务并持久化之后的磁盘状态
- undo-redo logs:同时包含before-image 和after-image 的记录内容,既撤销不应该出现的磁盘内容,又重做应该变更的磁盘内容。
日志格式描述约定:下面的描述中使用以下表达式表示对应的日志内容:
<start T>事务开始<commit T>事务提交<abort T>事务放弃<T, X, V>更改操作。事务T修改了数据对象X的值,其before-image原本值(或者after-image修改后的值)为Vflush logs将日志写入磁盘
undo logs
一个undo日志的例子:
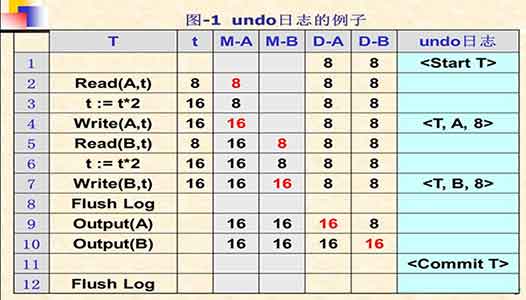
规则:
<T, X, V>更改操作日志必须在更改真正写入磁盘之前写入磁盘。<Commit T>在T的所有更新都写入磁盘后才能写入这条日志到磁盘。
根据undo日志恢复:
找到日志中有<start T>但是无<commit T>的事务,将其数据库更改撤销:从尾到头(从新的日志到旧的日志)扫描,如果碰到一个更改操作,操作的事务是T,若没有在之前扫描到<commit T>,就把这一条涉及的数据对象更改为日志中记录的之前的值。
但是undo日志会导致写操作有很多次,降低了效率。
redo logs
一个redo日志的例子:
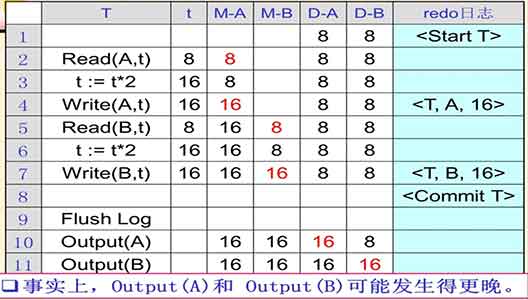
规则:<commit T>必须在更新值写入之前写入磁盘。
redo日志的回复:先找出所有已提交事务,然后从旧到新扫描日志,如果遇到每一条更改操作日志是已提交的事务所做的,则将记录的更改后的值写入磁盘;如果是未提交的事务就不管,继续扫描。最后给所有未提交事务加入一条<abort T>的放弃记录。
undo-redo logs
一个undo-redo日志的例子:
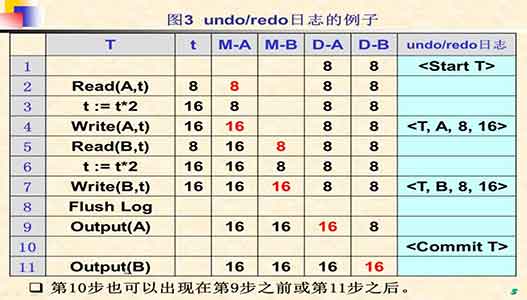
规则:
- 在T更新写入磁盘前,更新记录日志
<T, X, V, W>必须先写入磁盘 - 在每一个
<commit T>后面应该紧跟flush log确保有记录的事务确实已经提交。
undo-redo日志的恢复:根据<commit T>有没有出现判断事务T有没有已经提交,然后:从新向旧扫描,撤销未提交事务的磁盘写入;再从旧向新扫描,重做已提交事务的磁盘写入。
检查点
为了避免在系统崩溃时要从头到尾读取恢复所有日志,因此需要在运行时每过一段时间设置一个日志的检查点。恢复时只需要处理最后一次检查点前后的日志即可。
检查点分为静止检查点和非静止检查点。静止检查点设立时会等待所有事务结束然后插入检查点日志<CKPT>,之后再继续开始处理事务。而非静止检查点设立时不会要求当前的事务停止。
undo 日志检查点
如果设立静止检查点,就要等待当前正在进行的事务全部commit或者abort掉,然后把检查点标志<CKPT>写入磁盘。恢复的时候只需要检查到上一次的检查点处即可。
非静止检查点设立时比较复杂:先写入一个<start CKPT(T1,T2,...,Tn)>到磁盘,其中 T1…Tn 是检查点设立时正在进行的事务列表,然后不再处理新的事务。等待列表中的事务全部结束后,写入<end CKPT>到磁盘中,重新开始接受事务。恢复:如果发现一个最新的完整检查点(有start和end标记),那么只需要扫描到检查点start即可;但是如果只找到一个检查点的start标记,那么说明设置检查点的时候崩溃了,这个时候要扫描到列表中所有事务的start之前。
redo日志检查点
通常设置非静止检查点:先写入一个<start CKPT(T1,T2,...,Tn)>到磁盘,其中 T1…Tn 是检查点设立时正在进行的事务列表。找到所有上次检查点以来已提交的事务,把他们的更新写入磁盘。最后,写入<end CKPT>到磁盘中。
恢复:如果发现一个最新的完整检查点(有start和end标记),需要将start列表中的事务和检查点之后的事务进行更新的重做;但是如果只找到一个检查点的start标记,那么要扫描到前一个完整的检查点处理。
undo-redo日志检查点
通常也是设置非静止检查点。和redo检查点的设置方法是一样的。
恢复时:撤销上次完整的检查点以来未commit的事务更改,并重做已经commit的事务。

